立場① データベースにデータの出し入れを指示する立場
立場② 立場①の人が、効率よく、安全にデータの出し入れができるよう必要なテーブル準備や各種設定を指示する立場
立場②としてテーブル作成などを指示する場合にも、SQLを使います。CREATE TABLEという命令を使います。立場②として使う命令はほかにもたくさん準備されていますが、すべてのSQL文は、最終的に次の3種類の命令に分類することができます。
DCLは、誰に、どのようなデータ操作やテーブル操作を許すかといった権限を設定するためのSQL命令の総称です。権限を付与するGRANT文と剥奪するREVOKE文があります。
GRANT 権限名 TO ユーザー名
REVOKE 権限名 FROM ユーザー名
これらは、立場②の中でも特にデータベースの全権を管理する、データベース管理者の立場の人だけが使う命令です。
テーブルを作成するには、CREATE TABLE文を使います。作成したいテーブルの名前、テーブルを構成する列と型の一覧を指定し、テーブルを定義します。
CREATE TABLE テーブル名(
列名1 列1の型名,
列名2 列2の型名,
:
列名X 列Xの型名,
)
これまで利用してきた家計簿テーブルを作成するには、以下のようなSQL文を実行します。
CREATE TABLE 家計簿(
日付 DATE,
費目ID INTEGER,
メモ VARCHAR(100),
入金額 INTEGER,
出金額 INTEGER,
)
あるテーブルに対してINSERT文によって行が追加される際、一部の列の値が指定されないことがあります。例えば、家計簿テーブルに行を追加する以下のリストのように、「費目ID」や「入金額」が省略されるかもしれません。
INSERT INTO(日付, メモ, 出金額)
VALUES('2013-04-12', '詳細は後で', 60000)
このSQL文が実行されると、テーブルに追加された行に「費目ID」と「入金額」の列の内容は、NULLになります。
テーブルを作成する際に、デフォルト値を決めておくことで、「特に指定しなければ入金額には0が格納される」というような設定を行うことが可能です。
そのためには、CREATE TABLE文にDEFAULTキーワードを指定します。
CREATE TABLE テーブル名(
列名 型名 DEFAULT デフォルト値,
:
)
データベース内に、同じ名前のテーブルを複数作ることはできないので、テーブルを作り直すには、テーブルをいったん削除しなければなりません。
テーブルそのものを削除するにはDROP TABLE文を利用します。
DROP TABLE テーブル名
テーブル定義の内容を変更するには、ALTER TABLE文を使います。この文では、具体的にテーブルの「何を」「どう」変えるかを指定する必要があります。
既存のテーブルに列を追加する場合、挿入される位置は、原則として一番最後になります。
データベースの利用者が、文法としては正しいものの、システムの意図としては誤ったSQL文をDBMSに送ってしまうような人為的ミスに対してトランザクション制御はまったくの無力です。「誤った内容のSQL文」が、「指示通りに正しく実行」されてしまいます。
DBMSは、人為的ミスによる意図しないデータの格納が行われないための仕組みをいくつも備えています。「型」もそんな安全機構の1つです。
予期しない値を格納できないように制限をかけることで、
人為的ミスによるデータ破壊の可能性を減らすことができる。
多くのDBMSは制約という仕組みを備えており、型よりもさらに強力な制限をかけることができます。
制約は、CREATE TABLE文でテーブルを定義する際に、列定義の末尾に指定することが可能です。
CREATE TABLE テーブル名(
列名 型 制約の指定,
:
)
制約を複数指定することもできますが、カンマで区切らずにそのまま並べて記述します。
【その1】NOT NULL制約
NOT NULL制約が設定された列には、NULLの格納は許可されません。
NOT NULL制約はDEFAULT指定と組み合わせて利用されることがほとんどです。デフォルト値が設定されていれば、INSERT文で特に値を入力しなくても自動的にその値が設定されるため、エラーにならないからです。
【その2】UNIQUE制約
ある列の内容が決して重複してはならない場合、UNIQUE制約を付けます。UNIQUE制約がかけられていても、NULLが格納された行が複数存在することは許されます。「NULLはNULLとも等しくない」からです。
【その3】CHECK制約
ある列に格納される値が妥当であるかを細かく判定したい場合は、CHECK制約を用います。CHECKの後ろのカッコ内に記述した条件式がTRUEとなるような値だけが格納を許されます。
主キーの役割を担う列には、主キー制約を付けましょう。この制約がついてる列は、単なる「NULLも重複も許されない列」ではなく、主キーとしての役割が期待されているという意味を持ちます。
主キーを付ける方法は2つあります。ある単独の列に指定したい場合は、ほかの制約と同様、列名の末尾に記述します。この記法を用いる場合、複数の列に主キー制約を指定することはできません。
CREATE TABLE 費目 (
ID INTEGER PRIMARY KEY,
名前 VARCHAR(40) UNIQUE
)
CREATE TABLE文の最後に記述する記法を用いれば複合キーの指定も可能です。
CREATE TABLE 費目 (
ID INTEGER,
名前 VARCHAR(40) UNIQUE,
PRIMARY KEY(ID, 名前)
)
主キーの列に関しては、万が一にもNULLや重複値が格納されると行が識別できないという致命的な状況に陥るため、特別な理由がない限り、主キー制約を指定するようにしましょう。
外部キーが指し示す先にきちんと行が存在してリレーションが成立していることを参照整合性といいます。外部キーで別テーブルの行を参照しているのに、その行が存在しないような、異常な状態になってしまうことは「参照整合性の崩壊」といわれ、データベース利用において絶対に避けなければならないことです。
参照整合性を引き起こすデータ操作には、次に挙げる4つのパターンがあります。
参照整合性が崩れるようなデータ操作をしようとした場合にエラーを発生させ、強制的に処理を中断させる制約が外部キー制約です。この制約は、参照元のテーブルの外部キー列に設定します。
CREATE TABLE文で外部キー制約をかけるには、次のような構文を利用します。
CREATE TABLE テーブル名 (
列名 型 REFERENCES 参照先テーブル名 (参照先列名)
:
)
主キーの場合と同様に、CREATE TABLE文の最後にまとめて定義することも可能です。この場合は、「FOREIGN KEY」で制約を付ける列を指定します。
CREATE TABLE テーブル名 (
:
FOREIGN KEY (参照元列名) REFERENCES 参照先テーブル名 (参照先列名)
)
あるページを検索する場合、記憶をたどりながらページをめくったり、最初のページからしらみつぶしに探していくなど、様々な方法が考えられます。しかし、最も効率がよいのは巻末の「索引」を使って検索することではないでしょうか。データベース内のテーブルに対しても、書籍の索引と似たものを作ることができます。
データベースで作成することのできる索引情報はインデックスと呼ばれ、次のような特徴があります。
インデックスを作成するには、DDLに属する命令であるCREATE INDEX文を使います。
CREATE INDEX インデックス名 ON テーブル名 (列名)
インデックス名は、他と重複しない範囲で好きな名前を付けることができます。この名前は、DROP INDEX文でインデックスを削除するときにも使います。
DROP INDEX インデックス名
DROP INDEX インデックス名 ON テーブル名--MySQLの場合
複数の列を1つのインデックスとする複合インデックスも作成可能です。
*実際にどのような検索にインデックスが利用されるかは、DBMSの種類やDBMSが採用するインデックスのアルゴリズムに依存する。
特に重要なのが2つ目のデメリットです。インデックスが作成されている列のデータを変更する場合、DBMSはそのたびにインデックス情報を更新する必要があり、更新処理に時間がかかるようになってしまうのです。
データベースを利用していると、同じようなSQL文を頻繁に実行していることに気付く場合があります。例えば、「4月のすべての入出金を表示する」および「4月に使った費目を一覧表示する」には、以下のSQL文を実行します。
SELECT * FROM 家計簿
WHERE 日付 >= '2013-04-01'
AND 日付 <= '2013-04-30';
SELECT DISTINCT 費目 ID FROM 家計簿
WHERE 日付 >= '2013-04-01'
AND 日付 <= '2013-04-30';
2つのSELECT文に同一のWHERE句が記述されています。4月についての検索を行うたび同じSQL文を書くのは面倒です。このような場合に便利なのが、結果表をテーブルのように扱えるビューという機能です。例えば、「SELECT文を使って家計簿テーブルから4月の分だけを抽出したもの」を「家計簿4月」ビューとして作成し、それをテーブルの様に利用することができます。
ビューの作成にはCREATE VIEW文を、削除にはDROP VIEW文を使います。
CREATE VIEW ビュー名 AS SELECT文
DROP VIEW ビュー名
ビューを使うことにより、SQL文がシンプルになります。
ビューにはもう1つメリットがあります。テーブルAのある列に機密情報が含まれており、一般の利用者にはその列を見せたくない状況があるとします。そのような場合、機密情報の列だけを除いたビューBを定義しておきます。GRANT文を使って、一般の利用者に対して「テーブルAはアクセス禁止、ビューBは許可」という設定をすることにより、データ参照を許可する範囲を利用者の立場に応じて適切に定めることができます。
テーブルとビューはまったく同じというわけではありません。テーブルに対しては自由にINSERTやUPDATEを行うことができますが、ビューに対してはいくつかの条件が揃わなければSELECTしか行うことができません。ビューの実体は単なる「名前を付けたSELECT文」でしかありません。
ビューを展開してしまうと、送信したSQL文は非常にシンプルであるのに対し、実際に実行されるSQL文は非常に複雑なものになってしまい、一見するよりも負荷の高い処理になる可能性があります。
あるテーブルに行を追加する場合、主キーの値を何にすべきか迷うことがあります。主キーである以上、すでに使われている値と重複することは許されませんので、連番を振るという方法がよく用いられます。追加する行に独自の番号振るために、適切な番号を取得することを採番とも言います。
開発現場では、すでに採番した番号や最後に採番した番号を、専用のテーブルに記憶しておくなどの手法が使われます。この記録用のテーブルは採番テーブルと呼ばれ、工夫次第では記号や数字が混じった独自の番号も重複することなく採番することが可能です。
(1)連番が自動的に振られる特殊な列を定義できる
SQL Server、MySQL、SQLite、PostgreSQLの場合、CREATE TABLE文で列を定義する際に「連番を振る列である」ことを指定するだけで、データが追加されるタイミングで自動的に連番が振られるようになります。
| DBMS | 連番列を定義する方法 |
|---|---|
| SQL Server | IDENTITY 修飾を付与 |
| MySQL | AUTO_INCREMENT 修飾を付与 |
| PostgreSQL | データ型にSERIAL型を利用 |
| SQLite | AUTOINCREMENT 修飾を付与 |
(2)連番を管理してくれる専用の道具が提供されている
Oracle DB、DB2、SQL server、PostgreSQLでは、専用の道具としてシーケンスが利用できます。シーケンスは常に採番した最新の値を記憶しており、シーケンスに指示をすることで「現在の値」や「次の値」を取り出すことができます。シーケンスから値を取り出すと、その操作はすぐに確定し、トランザクションをロールバックしてもシーケンスの値は戻りません。
シーケンスは、CREATE SEQUENCE文で作成し、DROP SEQUENCE文で削除することができます。
CREATE SEQUENCE シーケンス名
DROP SEQUENCE シーケンス名
*CREATE SEQUENCE文には、「デフォルト値」や「一回の採番で増やす値」「最大値」などのオプションが指定可能。
シーケンスから値を取り出す方法はDBMS製品によって大きく異なります。Oracle DBやDB2では、シーケンスを疑似的テーブルとみなし、SELECT文を使うことで値を取り出したり、次の値に進めたりできます。
Oracle DBでは、シーケンスを作成した直後にCURRVALで現在の値を取得することはできません。現在の値を知るには、必ず、NEXTVALでシーケンスを次の値に進めておく必要があります。
PostgreSQLでは、SELECT文ではなく関数を使ってアクセスします。
INSERT文中の副問い合わせとして記述すれば、シーケンス値の採番と同時にデータを追加することができます。
ITの世界では、「データを正確かつ安全に取り扱うためのシステムが備えるべき4つの特性」として、ACID特性というものが広く知られています。ACIDとは、これまでに学んできた中の原子性、一貫性、分離性と永続性を言います。
多くのDBMSは、万が一のデータ消失に備えてバックアップの仕組みを備えています。それは、全内容をファイルに出力することができる、というものです。バックアップは毎日や毎週など定期的な感覚で自動的に行われるように設定されます。
整合性を保ちつつバックアップを行うもっとも簡単な方法は、データベースを停止してからバックアップを行うオフラインバックアップです。しかし、オフラインバックアップ中は一切のデータ処理が行えなくなります。データベースやそれを使ったシステムが停止してしまうことは状況によっては許されないかもしれません。
そのため、多くのDBMSは、稼働しながら整合性のあるバックアップデータを取得できるオンラインバックアップ機能も備えています。
バックアップは時間がかかる処理なので、あまり頻繁に行うわけにはいきません。しかし、バックアップを1日1回だけにしてしまうと、それまでにディスクが壊れてしまった場合、それまでの処理結果がすべて失われてしまいます。
このようなことにならないように、通常のバックアップなどは低い頻度で行う代わりに、データベースが出力するログファイルを10分周期や1時間周期といった高頻度でバックアップするのです。
データベースのログは、REDOログまたはトランザクションログなどと呼ばれ、その内容は「それまでに実行したすべてのSQL文」にほかなりません。ログファイルを高い頻度でバックアップしておくと、データ消失時にも以下のような手順を踏むことで、消失直前の時点までデータを復元することができます。
ログに記録されているSQL文を再実行して、障害が発生する直前の状態までデータを更新する処理のことをロールフォワードと言います。
SQLやDBMSの機能に関する知識だけでは、データベースを用いたシステムは開発できない。要件をしっかりと理解し、その要件をデータベース設計に適切に落としむための方法論を活用しなければならない。
システム開発の一環としてデータベースを作ろうとする場合、使える材料(INPUT)と、作るべきもの(OUTPUT)を明確にすることが大切です。
概念設計では、要件を実現するために、抽象的な概念としてどのような「情報の塊」を管理しなければならないかを明らかにします。この情報の塊のことをエンティティといい、通常エンティティは複数の属性を持っています。
エンティティ ・・・「テーブル」のようなもの
属性 ・・・テーブルの「列」のようなもの
関係 ・・・「リレーション」のようなもの
概念設計の成果は、ER図という図にまとめることが一般的です。ER図を使うことで、エンティティ、属性、リレーションをふかんして見ることができます。
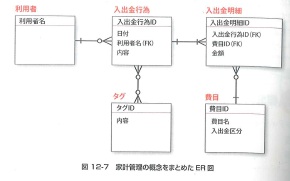
ER図には、IEという形式と、IDEF1Xという2つの記述形式があります。
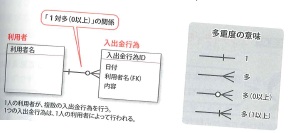
ER図に登場する四角形はエンティティを表しています。四角形の上にはエンティティの名前が、中には属性の一覧が記述されます。属性の一覧は、2つのグループに分けられます。四角形の中の線より上には、エンティティを一意に特定する主キーとなる属性を記述します。複数の属性で複合キーを構成する場合、線より上に複数の属性が記述されます。複数のエンティティ間にリレーションがある場合には、エンティティ同士を線で繋ぎ、外部キーとなる属性には「FK」と付記します。エンティティ同士の数量的な関係を多重度やカーディナリティと言います。
【ステップ1】候補となる用語を洗い出す
【ステップ2】不要な用語を捨てる
【ステップ3】関連がありそうなものをまとめる
【ステップ4】
ER図では、エンティティの中にエンティティを作ることはできません。別のエンティティとして、外部に取り出すようにしましょう。外部に取り出したエンティティは、元のエンティティと関係があるはずです。元のエンティティと関連付けれるように、取り出したエンティティに元のエンティティの主キーを属性として追加しておきます。
概念上のエンティティをリレーショナルデータモデルで取扱いやすい形のテーブルに変形する。
どのような変形を行えばいいか、論理設計の流れを確認します。
リレーショナルデータベースは「多対多」の関係をうまく扱うことができません。2つのエンティティの対応を格納した中間テーブルを追加することによって、「多対多」を2つの「1対多」の関係に変換します。
出揃ったすべてのエンティティのキーについて整理と確認を行います。特に重要なのは主キーです。主キーを持たないエンティティには、管理をしやすくするために人工的な主キーを追加します。
論理設計におけるもっとも中心的な作業は、正規化の作業です。正規化とは、矛盾したデータを格納できないよう、テーブルを複数に分割していく作業です。正規化という手法を用いて正しくテーブルを分割することにより、ヒューマンエラーを防止することができます。
正規形は第1正規形から第5正規形まで存在します。通常のシステム開発が目的の場合は、業務で求められる第3正規形までしていれば問題ないでしょう。
テーブルのすべての行のすべての列に1つずつ値が入っているべきである。
よって、繰り返しのセルやセル結合が現れてはならない。
(ある列Aの値が決まれば、自ずと列Bの値も決まる)という関係。このとき、列Bは列Aに関数従属している。このことを関数従属性という。
テーブルに含まれる主キー以外の列は、主キーの列に対して関数従属しているべきなのです。テーブルの列が何らかの理由で「主キーに汚く関数従属してしまう」ことがあります。これを排除することこそ、第2正規形の目的です。
複合キーを持つテーブルの場合、非キー列は、複合主キーの全体に関数従属するべきである。よって、「複合主キーの一部の列に対してのみ関数従属する列」が含まれてはならない。
*複合主キーの一部の列にしか関数従属しない状態を、部分関数従属と言います。
部分関数従属を排除し、第2正規従属に変形するには、次の順番を実施します。
テーブルの非キー列は、主キーに直接、関数従属すべきである。
よって、「主キーに関数従属する列にさらに関数従属する列」は存在してはならない。
*間接的に関数従属することを、推移関数従属と言います。
次のような手順を踏んで、推移関数従属を排除します。
第1正規形への変形:繰り返し列
第2正規形への変形:複合主キーの一部への関数従属
第3正規形への変化:間接的な関数従属
管理するときは・・・データは複数のテーブルに分割してある方がよい。
利用するときは・・・データは1つのテーブルに結合してある方がよい。
人間にとってはあまり正規化されていない情報の方が取扱いやすいので、結合をたくさん使うのは、ある程度仕方ないことと言えます。